rqlite is a lightweight, open-source, distributed relational database. It’s written in Go, built on the Raft consensus algorithm, and uses SQLite as its storage engine. With release 8.32, rqlite now supports fast, reliable, Linearizable reads—delivering strong consistency guarantees without the performance costs of the past.
is a lightweight, open-source, distributed relational database. It’s written in Go, built on the Raft consensus algorithm, and uses SQLite as its storage engine. With release 8.32, rqlite now supports fast, reliable, Linearizable reads—delivering strong consistency guarantees without the performance costs of the past.
Distributed systems present many challenges, but there is only one really hard problem: ensuring a consistent state across nodes, even in the face of network partitions, machine failures, or unexpected bugs. And a closely related requirement is ensuring up-to-date data reads — both requirements are the essential challenges that every distributed database must address.
Let’s examine how the latest release of rqlite approaches read consistency, balancing performance with data correctness. We will examine why the new feature, Linearizable reads, is important, how it improves upon existing methods, and how it delivers both speed and accuracy.
The Importance of Read Consistency in Distributed Systems
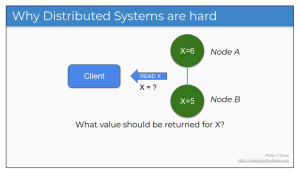 Depending on your application, ensuring that the data you read from a distributed is up-to-date can be critical. The system’s ability to return the most recently-written data is governed by its read consistency model.
Depending on your application, ensuring that the data you read from a distributed is up-to-date can be critical. The system’s ability to return the most recently-written data is governed by its read consistency model.
Different distributed systems offer various trade-offs between speed and correctness. Some prioritize speed and availability, at the risk of returning outdated data, while others guarantee the freshest data but come with a performance cost.
In rqlite, controllable read consistency has always been central to its design. However, choosing between its existing levels—Weak and Strong—meant trading performance for correctness. With the introduction of Linearizable reads in rqlite 8.32, this trade-off becomes much less pronounced.
Let’s look at each read consistency level, and how they work.
Weak Consistency: Fast but Not Foolproof
One of the simplest ways to handle reads in a Raft-based distributed system is by directly querying the Leader node. If the node believes it is the current Leader, it reads the data from its local store. This is how rqlite’s Weak consistency level operates—fast, simple, and, in most cases, reliable.
However, Weak reads come with a notable risk. If the node serving the request has been deposed as Leader but has not yet detected it, it may return stale data. This can occur because the node has not received updates from the new Leader, leaving a brief window (usually less than a second) where outdated data could be returned.
As the rqlite documentation explains about Weak:
A node checks if it’s the Leader by checking state local to the node, so this check is very fast. However there is a small window of time (less than a second by default) during which a node may think it’s the Leader, but has actually been deposed, a new Leader elected, and other writes have taken place on the cluster. If this happens the node may not be quite up-to-date with the rest of the cluster, and stale data may be returned. Strictly speaking, Weak reads are not Linearizable.
In most stable clusters, this risk is minimal. Even Hashicorp Consul, built on the same Raft implementation as rqlite, defaults to Weak reads too (Consul actually uses the term default instead of Weak). The speed and simplicity of Weak reads make them suitable for most applications, but the potential for stale reads may not be acceptable in environments that require guaranteed consistent data.
Strong Consistency: Accurate but Costly
For applications where up-to-date data is essential, rqlite has long offered Strong consistency, which eliminates the risk of stale data. In this mode, read requests are processed through the same Raft consensus mechanism used for writes. This ensures that the node serving the request remains the Leader throughout the entire read process and that the data returned to the client reflects all previously completed writes. This is the definition of a linearizable read.
However, this correctness comes at a performance cost. Strong reads require consensus across a quorum of nodes and involve additional disk I/O, leading to substantially higher latency relative to Weak reads. For systems with frequent reads, this overhead can accumulate, making Strong reads impractical for applications where performance is paramount.
Introducing Linearizable Reads: The Best of Both Worlds
With the release of rqlite 8.32, there is now a way to achieve the same strong consistency guarantees without incurring the performance penalty: Linearizable reads.
Linearizable reads ensure that the node serving the read remains the Leader throughout the process, similar to Strong reads. However, instead of sending the read request through the Raft log, the Leader first performs the read, and then heartbeats with the other nodes in the cluster. If the Leader receives a successful response from at least a quorum of nodes in the cluster, it can be certain it was Leader throughout the read process. In this way the node can be sure that the data it read accounts for all writes that completed before the read started — which means we’ve again got linearizable reads.
This approach significantly reduces the latency associated with Strong reads while preserving the same level of consistency. As a result, Linearizable reads provide the best of both worlds—strong guarantees without the performance cost.
Implementation in the Real World
Interestingly, the Raft disseration doesn’t explicitly specify every detail of its Linearizable Read optimization (Section 6.4). For example the paper makes an assumption that no Leader Election takes place that ends up re-electing the same Leader, but real-world systems have to check for this. Also the Hashicorp library, on which rqlite is built, doesn’t actually make it possible to perform the optimization properly. There is an open pull request to fix this, but in the meantime rqlite has to upgrade its first Linearizable Read to Strong to account for this.
Test Results
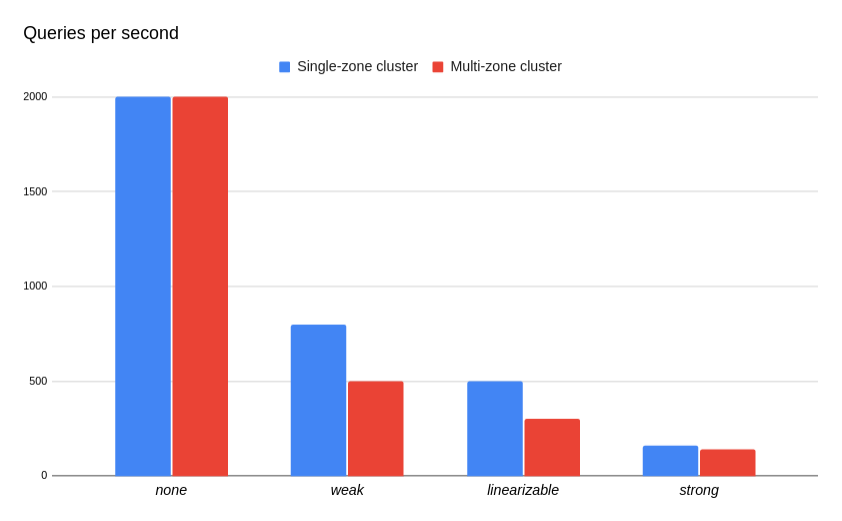
So how much faster are Linearizable Reads? To check, let’s spin up two 3-node rqlite clusters on Google Cloud (e2-standard-4 virtual machines, with SSDs). The first cluster – the single-zone cluster – places all 3 nodes in a single GCP zone. In a single zone ping time between nodes is about half a millisecond. The second cluster — the multi-zone cluster — places each node in a different zone (but within the same region). In this case the ping time is about 1.5 milliseconds.
Testing shows that Linearizable Reads are substantially faster than Strong Reads. While Linearizable is measurably slower than Weak, multiple Linearizable Reads can take place in parallel, just like Weak. In other words one Linearizable Read won’t block another, which is not the case with Strong.
It’s important to note that the test results below are only from one Reader. The aggregate read performance of rqlite can be much higher, as many other clients can be reading at the same time and getting the same read performance (with the important exception of Strong read consistency). Finally, none consistency reads are also shown for comparison sake.
Why It Matters: Faster, Reliable Consistency
The new Linearizable reads in rqlite 8.32 offer an ideal solution for applications that require both high performance and strong consistency. Whether managing a distributed system or developing a high-performance application, selecting the appropriate read consistency model is crucial.
With Linearizable reads, you no longer need to compromise between performance and correctness. You can ensure that your reads are both fast and accurate, making rqlite an even more powerful tool for developers seeking robust distributed database solutions.
As always, feedback and contributions from the community are very welcome. To learn more about Linearizable reads and how to use them in your projects, visit the rqlite documentation or join the discussion in our Slack channel.